Introduction
In your company, you want your resources to be available most of the time. You also want a secondary resource, or group of resources, ready to be used if the primary resources become unavailable. With Amazon Route 53, when all primary resources are unhealthy, Route 53 responds to DNS queries using only the healthy secondary resources.
Disaster Recovery Mechanisms Using Amazon Route 53
By switching traffic, you reduce the impact of failures and then return to normal operation. This process is called failover. To use failover, many companies change their DNS records. You can have different record types, but the DNS name stays the same so users do not notice the change.
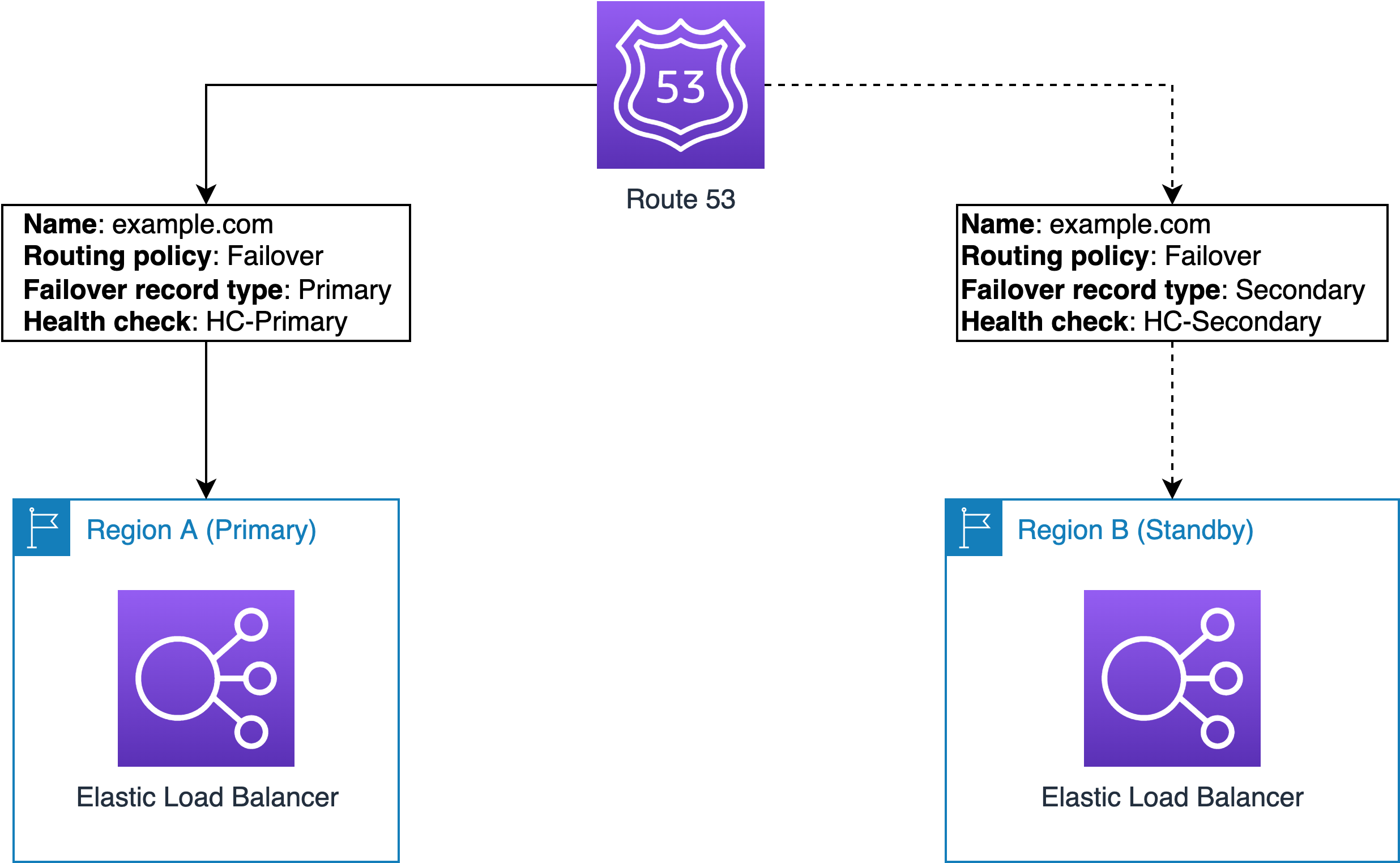
Designing a reliable failover mechanism
A failover mechanism must be reliable and available when you need it. I wanted to apply my previous chaos engineering experience here.
For me, automated tests are chaos experiments. When using a failover mechanism, it is important to run many tests to build confidence that it will work when a real problem happens.
A simple experiemtn which make stop all instance and then the web server will not answer and the health endpoint also has not work.
Remenber to apply the experiment is on the primary region. AWS FIS is not global service.
|
|
Invert primary <=> secondary on AWS Route 53 DNS Failover setup
If my primary web server has a heavy load and becomes slow, the health check for the primary server fails. Route 53 then fails over the A record to my secondary web server.
This helps because the primary server no longer receives most of the traffic. As a result, it recovers, the health check passes again, and the system is healthy.
That’s the workflow…
Demo
I did the small experiment…
Conclusion
To learn more about Resolution Name server and the types is really important.